Klaudius is a pipeline that runs in one terminal. It finds businesses without websites, builds each one a bespoke site from photos and data it scrapes, deploys it, and sends the business owner the live URL. By the time you check back, a stack of business owners are looking at the website Klaudius built for them.
Today, that pipeline is a parent claude session orchestrating three concurrent claude -p children, each handling one client end-to-end. Find, gather, build, QA, deploy, outreach. Three at a time. The parent refills any slot that finishes. Forever, until you stop it.
On June 15, 2026, the infrastructure underneath that design stops being economic.
Here is what Anthropic changed, why every operator running an autonomous Claude Code pipeline is asking the same question this week, and what Team Klaudius landed on so that the pipeline keeps running on a single Claude subscription.
What Anthropic changed
On May 13 the @ClaudeDevs account posted this announcement, reposted by Boris Cherny, the Claude Code team lead:
Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage. The credit covers usage of:
- Claude Agent SDK
claude -p- Claude Code GitHub Actions
- Third-party apps built on the Agent SDK
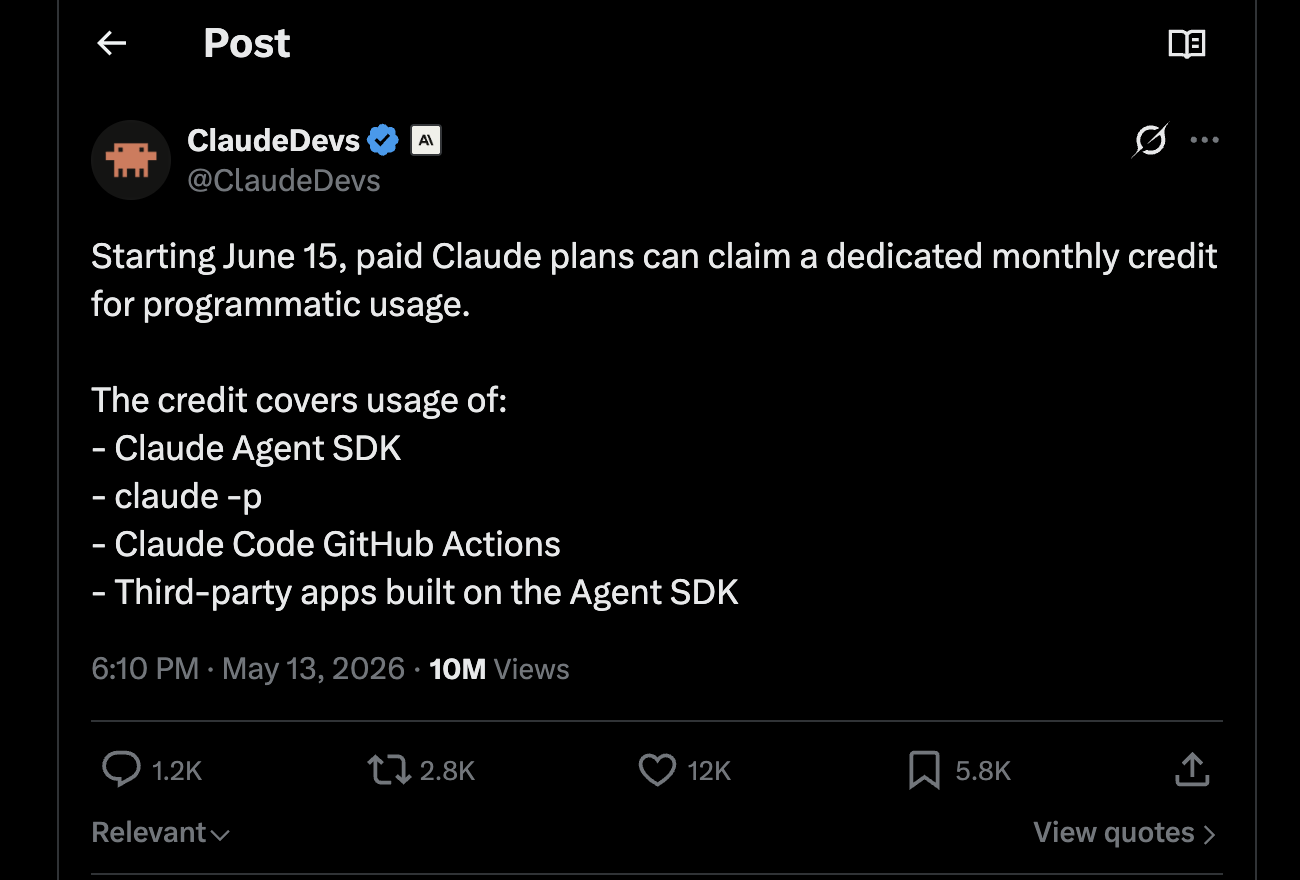
The credit is $20 on Pro, $100 on Max 5x, $200 on Max 20x, billed at full API rates, with no rollover.
What is explicitly NOT in the credit pool, and stays on the regular subscription pool: "Interactive Claude Code in the terminal or IDE", the chat product, and Cowork.
The list is short and enumerative. Four things go to the metered pool. Everything else stays on subscription.
Why this hurts operators
Run the math on Klaudius's pipeline today. One end-to-end client build (find, site, outreach) at Opus 4.x API rates, with cache discounts factored in, lands at roughly $14 per client.
At $200/month credit on a Max 20x plan, you get about 15 builds per month before usage spills to API overage. After that you either pay overage rates (if you turned overage on) or the pipeline stops.
15 builds a month is not autonomy at scale. It is a part-time hobby. The whole point of the parent-orchestrator pattern, the whole reason you walk away from a terminal that has the pool running, is sustained operation that drops dozens, then hundreds, of warm leads into inboxes by Monday morning. Capping the pipeline at 15 builds defeats the model.
If you are running anything similar today (a content engine, a sales-prospecting loop, a research agent) the same math applies.
The ambiguity that mattered most
We spent half a day on one load-bearing question: what exactly triggers the gating?
Two readings of Anthropic's announcement:
- Literal. The gate fires when
argvcontains-p. - Functional. The gate fires for any "non-interactive Claude Code invocation", regardless of flag.
The help-centre article is ambiguous. It describes the flag as "claude -p command in Claude Code (non-interactive mode)", treating flag and mode as synonymous.
Why this matters: if the gate is functional, any workaround that hides a headless Claude Code session behind a wrapper gets caught. If the gate is literal, anything that is not a -p invocation is fine.
We posted the question to Boris and the @AnthropicAI account on X. At the time of writing we have yet to receive a response.
What didn't work
Before landing on the answer, we ruled out the obvious alternatives.
Tmux plus interactive claude wrapped in a Bash loop. Spawn claude interactive inside tmux, drive it with send-keys, use a Stop hook for self-termination, repeat. This is the workaround currently being floated by other operators publicly. The catch: true first-party subscription billing in this shape requires a real TTY attachment (the consensus on the operator forums calls this an open gap Anthropic could close), and the Stop hook is being asked to handle process kill. The model itself safety-refuses kill $PPID in our tests. Workable, but ugly, brittle, and structurally weaker than the answer below.
A sub-agent orchestrator using the Agent tool. Looked elegant on paper: one parent session, N sub-agents, each one a pipeline run. Blocked by a Claude Code constraint that hits hard. Sub-agents cannot spawn other sub-agents (Claude Code issue #19077). Klaudius's QA step itself spawns a qa-reviewer agent, so this is non-negotiable. Worse, when an agent is asked to spawn another agent, the failure is silent: it quietly does the work itself and reports a delegated outcome that never happened. Architecturally unsafe, regardless of billing.
Tmux send-keys to a single long-running session, reused for every client. Posted publicly by another operator the day before the change. Works for one-off scripted prompts. Breaks Klaudius's hard invariant of per-client fresh context: by client 30 the session is bloated; by client 50 it is degrading the work. Every Klaudius client build must start with an empty 200k window.
Third-party proxy services that re-route API calls through a stealth path. The community's own assessment is "high account-risk", which is the polite version of "we expect Anthropic to ban accounts that try this". Not on the table.
Just pay API overage. $14 × 100 client builds is $1,400/month per operator, just for the model. The entire economic case of Klaudius assumes a flat subscription. Not on the table either.
The answer: claude --bg and orchestrator-as-watcher
About a week before the June 15 announcement, Anthropic shipped agent view / background sessions in Claude Code v2.1.139:
claude --bg "<prompt>"dispatches a full Claude Code session that runs in the background under a separate supervisor process (~/.claude/daemon), independent of any terminal.claude agentsopens a TUI showing every running background session by state.- Each session's state is persisted at
~/.claude/jobs/<id>/state.json. - You can
claude attach <id>and step into any session interactively at any time. They are not headless. They are deferred interactive.
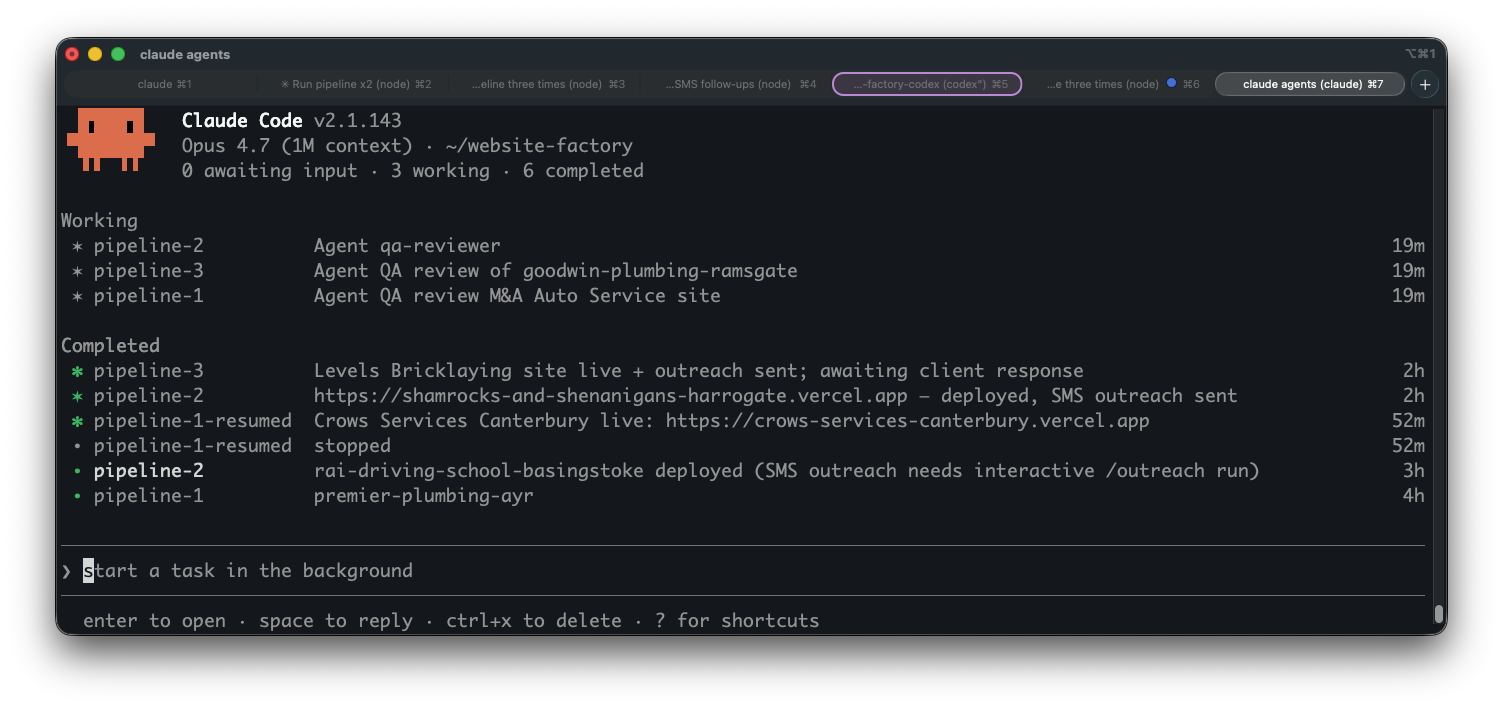
claude agents TUI with a pool of Klaudius pipeline sessions in flight.Crucially, claude --bg stays on the subscription pool. The official Anthropic agent-view docs are explicit:
Background sessions consume your subscription usage the same as interactive sessions, so running ten agents in parallel uses quota roughly ten times as fast as running one.
That wording was published with the credit-pool split already public knowledge inside Anthropic. The structural argument lines up: a --bg session is a fully attachable Claude Code session, not the one-shot non-interactive automation primitive that -p is. Treating them the same would be a category error.
Four supporting facts, in case the docs aren't enough on their own:
- Anthropic's June 15 announcement enumerates four things in the credit pool.
--bgis not one of them. The list is not hedged with "and similar". - Boris Cherny reposted the announcement without flagging
--bg. He runs Claude Code, he shipped--bga week earlier, and he is demonstrably responsive on X. His silence on--bgin that context is meaningful. - The agent-view docs explicitly say background sessions count against subscription quota.
- Timing.
--bgshipped one week before the announcement. That looks intentional.
In short: if you run Klaudius on a Claude subscription, the pool of --bg children Klaudius spawns counts against that subscription's quota, exactly the way the interactive parent does. No API rates. No metered credit pool. No overage bill.
The pipeline shape, before and after
Klaudius today vs. after June 15: same parent orchestrator, same control loop, supervisor process inserted between the parent and the children.
Structurally identical. The supervisor sits in between, but the parent's mental model is unchanged: pool of N concurrent client builds, refill on completion, escalate on consecutive failures.
The mechanical change: a two-step dispatch
The one trick that took an evening to settle. claude --bg returns immediately with a session ID. The work continues in the background. So a single bash cannot both capture the ID and block on completion. The dispatch needs two bashes.
Step 1, foreground Bash, capture the session ID:
claude --bg --name "pipeline-1" "Run the pipeline"
# → backgrounded · a3f9b21cStep 2, background Bash, block until done and emit the result:
ID=a3f9b21c
until [ "$(jq -r .state ~/.claude/jobs/$ID/state.json 2>/dev/null)" = "done" ]; do
sleep 5
done
jq -r '.output.result // "(no result captured)"' ~/.claude/jobs/$ID/state.jsonThe second bash returns to the orchestrator immediately with a task ID, then continues in the background. When the supervisor flips state to done and the bash exits, the harness fires a <task-notification> back to the orchestrator carrying the final string the child emitted as its closing assistant message.
That <task-notification> is the wake signal. The model is identical to today's parent-orchestrator: a backgrounded bash exits, the harness fires the notification, the orchestrator handles it. Today it's a -p child finishing. Tomorrow it's a --bg watcher seeing state == done.
Orchestrator-as-watcher
Our first cut was a deterministic shell watcher that parsed output.result with a regex (^SUCCESS \| <slug> \| ...). The orchestrator just spawned the watcher and acted as the natural-language interface.
We pivoted, fast. The model paraphrases strict return formats unreliably. "pipeline complete: test-abc passed", "SUCCESS: deployed test-c904 to https://...", "wrote done.txt for test-eb9, sent email" are all valid successes from the model's perspective. None of them are anchored at ^SUCCESS. The regex failed all three. Across a test run, three real successes were classified as failures, and the failure threshold tripped after three consecutive false negatives. The work was correct. The parser was wrong.
The reframe: let the orchestrator do the classification in natural language. It already has the entire history of the run in its window. It can read the child's final message, reason about whether the work succeeded, handle partial outcomes ("deployed, but the URL looks weird, call that a soft-fail and refill"), and tell the operator what happened in plain English. The regex can never do any of that.
So the orchestrator does both: dispatch and watch. Pseudocode, heavily simplified:
slots = N
failure_streak = 0
on_start:
for slot in 1..slots:
id = dispatch_bg("Run the pipeline") # foreground bash
spawn_wait(id) # background bash, returns task id
on task_notification(slot, output):
if reads_as_success(output): # natural-language judgement
failure_streak = 0
else:
failure_streak += 1
if failure_streak >= 3:
run "scripts/notify.sh \"<reason>\""
stop
id = dispatch_bg("Run the pipeline") # refill that slot
spawn_wait(id)That's the entire control loop. Same shape Klaudius has always had.
An accidental upgrade
There is a subtle but real win in this change that we did not see coming.
With claude -p, each child was an opaque bash process. You could read its stdout when it finished, but until then, "what is it actually doing right now?" was unanswerable. If a child got stuck on a tool call, you saw nothing until the timeout fired. Debugging a misbehaving pipeline run meant tailing logs in a separate terminal and squinting.
With claude --bg, every child is a fully attachable Claude Code session. claude agents shows you live state for every one of them in a TUI. If session two is grinding through QA and seems too slow, you press enter on it from the agents TUI and you're inside that session, looking at its current message, its tool history, what it is about to do next. Detach and it keeps going. The supervisor does not care.
That changes the autonomous-operator experience from fire-and-forget-hope-nothing-breaks-debug-postmortem to fire, walk away, glance whenever you want, drop in if anything looks off. We did not ask for this. We inherited it because Anthropic's response to autonomous pipelines was a supervised process tree instead of a billing nerf.
A pitfall we hit
One trap worth flagging for any pipeline that touches macOS-protected resources (Contacts, Screen Recording, Accessibility, Full Disk Access, anything else in the TCC privacy categories).
claude --bg hands the work to a long-lived supervisor daemon that detaches into its own session, independent of iTerm. That detachment matters. macOS TCC decisions are inherited from the parent process. claude -p children inherited the parent terminal's TCC grants automatically. The --bg daemon does not.
So if your pipeline reaches into any TCC-protected resource, the -p version worked silently and the --bg version fails silently. No loud error in the supervisor's logs.
The fix, with two non-obvious bits:
- Grant the relevant TCC permission to the versioned binary (
~/.local/share/claude/versions/<v>/claude), not the~/.local/bin/claudesymlink. TCC keys on the file. The symlink and the resolved binary can hold separate decisions in TCC, and the real binary's decision is what counts. - Re-grant after every Claude Code version bump. A new version is a new file. TCC reverts silently otherwise.
Smoke-test in a fresh --bg session by asking it to perform the TCC-protected operation your pipeline needs and report stdout/stderr verbatim. Clean result: you're good. authorization denied: grant the versioned binary, kill the daemon, retry.
Why this matters past Klaudius
If you are running anything autonomous on claude -p today, you have 30 days to either:
- Eat the credit-pool cost (about 15 builds a month, then API overage), or
- Switch to a tmux-style workaround and absorb the brittleness, or
- Move to
claude --bgwith an orchestrator-as-watcher and keep running on your existing subscription.
We think the third option is the most aligned with where Claude Code is going. The supervisor process exists. The agent-view TUI exists. The docs explicitly bless subscription-billed background usage. Anthropic is telling you what the supported shape of "many concurrent Claude Code sessions" looks like, and it is not -p.
Where this lives in Klaudius
This is the orchestration pattern that runs the Klaudius pipeline. If you want to operate it yourself, pointed at a region of your choice, on your own machine, with your own credentials, that is what we sell at klaudius.dev. One licence, one operator, lifetime updates.
Whatever else you do this month, get off claude -p before June 15.
Team Klaudius